2.08. Проверка значимости параметров . линейной регрессии и подбор модели с использованием f-критериев
Приводимая ниже таблица содержит ежегодные данные о следующих показателях экономики Франции за период с 1949 по 1960 годы (млрд. франков, в ценах 1959 г.):
Y — Объем импорта товаров и услуг во Францию;
X2 — Валовой национальный продукт;
X3 — Потребление семей;
|
Obs |
Y |
X2 |
X3 |
X4 |
Obs |
Y |
X2 |
X3 |
X4 |
|
1949 |
15.9 |
149.3 |
4.2 |
108.1 |
1955 |
22.7 |
202.1 |
2.1 |
146.0 |
|
1950 |
16.4 |
161.2 |
4.1 |
114.8 |
1956 |
26.5 |
212.4 |
5.6 |
154.1 |
|
1951 |
19.0 |
171.5 |
3.1 |
123.2 |
1957 |
28.1 |
226.1 |
5.0 |
162.3 |
|
1952 |
19.1 |
175.5 |
3.1 |
126.9 |
1958 |
27.6 |
231.9 |
5.1 |
164.3 |
|
1953 |
18.8 |
180.8 |
1.1 |
132.1 |
1959 |
26.3 |
239 |
0.7 |
167.6 |
|
1954 |
20.4 |
190.7 |
2.2 |
137.7 |
1960 |
31.1 |
258 |
5.6 |
176.8 |
Выберем модель наблюдений в виде
![]()
Где ![]() — значение показателя
— значение показателя ![]() в I-М наблюдении (I-Му наблюдению соответствует
в I-М наблюдении (I-Му наблюдению соответствует ![]() год, и
год, и ![]() (значения «переменной»
(значения «переменной» ![]() , тождественно равной единице). Будем, как обычно, предполагать что
, тождественно равной единице). Будем, как обычно, предполагать что ![]() ~ I. i. d.
~ I. i. d. ![]() и что значение
и что значение ![]() Нам не известно. Регрессионный анализ дает следующие результаты:
Нам не известно. Регрессионный анализ дает следующие результаты: ![]() и
и
|
Переменная |
Коэф-т |
Ст. ошибка |
T-статист. |
P-знач. |
|
X1 |
–8.570 |
2.869 |
-2.988 |
0.0153 |
|
X2 |
0.029 |
0.110 |
0.267 |
0.7953 |
|
X3 |
0.177 |
0.166 |
1.067 |
0.3136 |
Обращают на себя внимание выделенные ![]() - Значения. В соответствии с ними, проверка каждой Отдельной гипотезы
- Значения. В соответствии с ними, проверка каждой Отдельной гипотезы ![]() ,
, ![]() (даже при уровне значимости
(даже при уровне значимости ![]() ) приводит к решению о ее неотклонении. Соответственно, при реализации каждой из этих двух процедур проверки соответствующий параметр
) приводит к решению о ее неотклонении. Соответственно, при реализации каждой из этих двух процедур проверки соответствующий параметр ![]() Или
Или ![]() признается Статистически незначимым. И это выглядит противоречащим весьма высокому значению коэффициента детерминации.
признается Статистически незначимым. И это выглядит противоречащим весьма высокому значению коэффициента детерминации.
По-существу, вопрос стоит таким образом: необходимо построить статистическую процедуру для проверки гипотезы
![]()
Конкретизирующей значения не какого-то одного, а Сразу двух коэффициентов.
И вообще, как проверить гипотезу
![]()
(гипотеза Значимости регрессии) в рамках нормальной линейной модели множественной регрессии
![]()
C ![]() ?
?
Соответствующий статистический критерий основывается на так называемой F-статистике
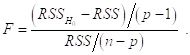
Здесь ![]() — остаточная сумма квадратов, получаемая при оценивании Полной модели (с
— остаточная сумма квадратов, получаемая при оценивании Полной модели (с ![]() объясняющими переменными, включая тождественную единицу), а
объясняющими переменными, включая тождественную единицу), а ![]() — остаточная сумма квадратов, получаемая при оценивании модели с наложенными гипотезой
— остаточная сумма квадратов, получаемая при оценивании модели с наложенными гипотезой ![]() ограничениями на параметры. Но последняя (Редуцированная) модель имеет вид
ограничениями на параметры. Но последняя (Редуцированная) модель имеет вид
![]()
И применение к ней метода наименьших квадратов приводит к оценке
![]()
Так что
![]()
Следовательно,
![]()
В некоторых пакетах статистического анализа (например, в EXCEL) в распечатках результатов приводятся значения числителя и знаменателя этой статистики (в графе Средние квадраты — Mean Squares).
Если ![]() ~ I. i. d.
~ I. i. d. ![]() , то указанная
, то указанная ![]() -Статистика, Рассматриваемая как случайная величина, имеет При гипотезе H0 (т. е. Когда действительно Q 2 = ¼= Q p= 0) стандартное распределение
-Статистика, Рассматриваемая как случайная величина, имеет При гипотезе H0 (т. е. Когда действительно Q 2 = ¼= Q p= 0) стандартное распределение ![]() , называемое F-распределением Фишера с (p-1) и (n-p) степенями свободы.
, называемое F-распределением Фишера с (p-1) и (n-p) степенями свободы.
Чем больше отношение ![]() , Тем больше есть оснований Говорить о том, что совокупность переменных
, Тем больше есть оснований Говорить о том, что совокупность переменных ![]() Действительно помогает в объяснении изменчивости объясняемой переменной
Действительно помогает в объяснении изменчивости объясняемой переменной ![]() .
.
В соответствии с этим, гипотеза
![]()
Отвергается при «слишком больших» значениях F, скорее указывающих на невыполнение этой гипотезы. Соответствующее пороговое значение определяется как квантиль уровня ![]() распределения
распределения ![]() , обозначаемая символом
, обозначаемая символом ![]() .
.
Итак, Гипотеза Н0 Отвергается, если выполняется неравенство
![]()
При этом, Вероятность ошибочного отвержения гипотезы ![]() равна
равна ![]() .
.
Статистические пакеты, выполняющие регрессионный анализ, приводят среди прочих результатов такого анализа также Значение ![]() Указанной
Указанной ![]() -Статистики и соответствующее ему P-значение (P-value), т. е. вероятность
-Статистики и соответствующее ему P-значение (P-value), т. е. вероятность
![]()
В частности, в рассмотренном выше примере с импортом товаров и услуг во Францию Вычисленное (наблюдаемое) значение ![]() -Статистики равно
-Статистики равно ![]() , в то время как критическое значение
, в то время как критическое значение
![]()
Соответственно, ![]() -Значение крайне мало — в распечатке результатов приведено значение
-Значение крайне мало — в распечатке результатов приведено значение ![]() . Значит, здесь нет Практически никаких оснований принимать Составную гипотезу
. Значит, здесь нет Практически никаких оснований принимать Составную гипотезу ![]() , хотя каждая из Частных гипотез
, хотя каждая из Частных гипотез
![]() и
и ![]() ,
,
Рассматриваемая Сама по себе, в отрыве от второй, Не отвергается.
Подобное положение встречается не так уж и редко и связано с проблемой Мультиколлинеарности данных. Далее мы уделим этой проблеме определенное внимание.
Что касается рассмотренных до этого примеров, то для них результаты использования ![]() -Статистики таковы.
-Статистики таковы.
Пример. Анализ данных об уровнях безработицы среди белого и цветного населения США приводит к следующим результатам:
![]() ,
, ![]() ,
, ![]() -Значение =
-Значение =![]() , так что при выборе
, так что при выборе ![]() гипотеза
гипотеза ![]() Не отвергается, а при выборе
Не отвергается, а при выборе ![]() Отвергается.
Отвергается.
Пример. Анализ зависимости спроса на куриные яйца от цены приводит к значениям
![]() ,
, ![]() ,
, ![]() -Значение =
-Значение = ![]() , так что гипотеза
, так что гипотеза ![]() Отвергается, а регрессия признается Статистически значимой.
Отвергается, а регрессия признается Статистически значимой.
Пример. Зависимость производства электроэнергии в США от мирового рекорда по прыжкам в высоту с шестом:
![]() ,
, ![]() ,
, ![]() -Значение =
-Значение = ![]() , регрессия признается Статистически значимой.
, регрессия признается Статистически значимой.
Пример. Потребление свинины в США в зависимости от оптовых цен:
![]() ,
, ![]() ,
, ![]() -Значение =
-Значение = ![]() , так что гипотеза
, так что гипотеза ![]() Не отвергается даже при выборе
Не отвергается даже при выборе ![]() .
.
Отметим, наконец, еще одно обстоятельство. Во всех четырех рассмотренных примерах регрессионного анализа модели Простой (парной) линейной регрессии (p=2) Вычисленные ![]() -Значения
-Значения ![]() -Статистик Совпадают с
-Статистик Совпадают с ![]() -Значениями
-Значениями ![]() -Статистик, используемых для проверки гипотезы
-Статистик, используемых для проверки гипотезы ![]() . Факт такого совпадения отнюдь Не случаен и может быть доказан с использованием преобразований, приведенных, например, в книге Доугерти (параграф 3.11).
. Факт такого совпадения отнюдь Не случаен и может быть доказан с использованием преобразований, приведенных, например, в книге Доугерти (параграф 3.11).
Применение критериев, основанных на статистиках, имеющих при нулевой гипотезе ![]() -распределение Фишера (F-критерии), отнюдь не ограничивается только что рассмотренным анализом статистической значимости регрессии. Такие критерии широко применяются в процессе Подбора модели.
-распределение Фишера (F-критерии), отнюдь не ограничивается только что рассмотренным анализом статистической значимости регрессии. Такие критерии широко применяются в процессе Подбора модели.
Пусть мы находимся в рамках множественной линейной модели регрессии
![]()
C ![]() объясняющими переменными, и гипотеза
объясняющими переменными, и гипотеза ![]() Состоит в том, что в модели
Состоит в том, что в модели ![]() Последние
Последние ![]() Коэффициентов равны нулю, т. е.
Коэффициентов равны нулю, т. е.
![]()
Тогда При гипотезе ![]() (т. е. в случае, когда она верна) мы имеем Редуцированную модель
(т. е. в случае, когда она верна) мы имеем Редуцированную модель
![]()
Уже с ![]() объясняющими переменными.
объясняющими переменными.
Пусть ![]() - остаточная сумма квадратов в полной модели
- остаточная сумма квадратов в полной модели ![]() , а
, а ![]() — остаточная сумма квадратов в редуцированной модели
— остаточная сумма квадратов в редуцированной модели ![]() . Если гипотеза
. Если гипотеза ![]() Верна и выполнены стандартные предположения о модели (в частности,
Верна и выполнены стандартные предположения о модели (в частности, ![]() ~ I. i. d.
~ I. i. d. ![]() ), то тогда F-Статистика
), то тогда F-Статистика
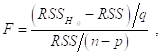
Рассматриваемая как случайная величина, имеет При гипотезе H0 (т. е. Когда действительно Q p = Q p-1 = ¼= Q p-q+1= 0) F-распределение Фишера F (q, n-p) с q и (n-p) степенями свободы.
В рассмотренном ранее случае проверки Значимости регрессии в целом Мы имели ![]() , и при этом там имело равенство
, и при этом там имело равенство ![]() которое Не выполняется в общем случае.
которое Не выполняется в общем случае.
Пусть
![]() — сумма квадратов, объясняемая Полной Моделью
— сумма квадратов, объясняемая Полной Моделью ![]() ,
,
![]() — сумма квадратов, объясняемая Редуцированной моделью
— сумма квадратов, объясняемая Редуцированной моделью ![]() .
.
Тогда
![]()
Так что ![]() -Статистику можно записать в виде
-Статистику можно записать в виде
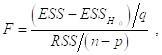
Из которого следует, что F-статистика измеряет, в соответствующем масштабе, Возрастание объясненной суммы квадратов вследствие включения в модель дополнительного количества объясняющих переменных.
Естественно считать, что включение дополнительных переменных Существенно, если указанное возрастание объясненной суммы квадратов Достаточно велико. Это приводит нас к Критерию проверки гипотезы
![]()
Основанному на F-статистике
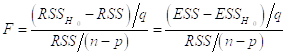
И Отвергающему гипотезу ![]() , когда Наблюдаемое значение
, когда Наблюдаемое значение ![]() этой статистики удовлетворяет неравенству
этой статистики удовлетворяет неравенству
![]()
Где ![]() — выбранный уровень значимости критерия (вероятность ошибки 1-го рода).
— выбранный уровень значимости критерия (вероятность ошибки 1-го рода).
Пример. В следующей таблице приведены данные по США о следующих макроэкономических показателях:
![]() — Годовой совокупный располагаемый личный доход;
— Годовой совокупный располагаемый личный доход;
![]() — Годовые совокупные потребительские расходы;
— Годовые совокупные потребительские расходы;
![]() — Финансовые активы населения на начало календарного года
— Финансовые активы населения на начало календарного года
(все показатели указаны в млрд. долларов, в ценах 1982 г.).
|
Obs |
C82 |
DPI82 |
A82 |
1971 |
1540.3 |
1730.1 |
1902.8 |
|
1966 |
1300.5 |
1433.0 |
1641.6 |
1972 |
1622.3 |
1797.9 |
2011.4 |
|
1967 |
1339.4 |
1494.9 |
1675.2 |
1973 |
1687.9 |
1914.9 |
2190.6 |
|
1968 |
1405.9 |
1551.1 |
1772.6 |
1974 |
1672.4 |
1894.9 |
2301.8 |
|
1969 |
1458.3 |
1601.7 |
1854.7 |
1975 |
1710.8 |
1930.4 |
2279.6 |
|
1970 |
1491.8 |
1668.1 |
1862.2 |
1976 |
1804.0 |
2001.0 |
2308.4 |
Рассмотрим модель наблюдений
![]()
Где индексу ![]() соответствует
соответствует ![]() год. Это модель с 4 объясняющими переменными:
год. Это модель с 4 объясняющими переменными:
![]()
Символ ![]() обозначает переменную, значения которой Запаздывают на одну единицу времени Относительно значений переменной,
обозначает переменную, значения которой Запаздывают на одну единицу времени Относительно значений переменной, ![]() . Оценивание этой модели дает следующие результаты:
. Оценивание этой модели дает следующие результаты:
![]()
![]()
![]()
![]()
![]()
![]() — статистика критерия Проверки значимости регрессии в целом
— статистика критерия Проверки значимости регрессии в целом
![]()
Регрессия имеет очень высокую статистическую значимость. Вместе с тем, каждый из коэффициентов при двух последних переменных Статистически незначим, так что, в частности, Не следует придавать особого значения отрицательности оценок этих коэффициентов.
Используя ![]() — критерий, мы могли бы попробовать Удалить из модели какую-нибудь одну из двух последних переменных, и если оставшиеся переменные окажутся значимыми, то остановиться на модели с 3 объясняющими переменными; если же и в новой модели окажутся статистически незначимые переменные, то произвести еще одну редукцию модели.
— критерий, мы могли бы попробовать Удалить из модели какую-нибудь одну из двух последних переменных, и если оставшиеся переменные окажутся значимыми, то остановиться на модели с 3 объясняющими переменными; если же и в новой модели окажутся статистически незначимые переменные, то произвести еще одну редукцию модели.
Рассмотрим, в этой связи, модель
![]()
С удаленной переменной ![]() . Для нее получаем:
. Для нее получаем:
![]()
![]()
![]()
![]()
F-Статистика критерия Проверки значимости регрессии в этой модели
![]()
Поскольку эдесь остается статистически незначимым коэффициент при переменной ![]() , можно произвести дальнейшую редукцию, переходя к модели
, можно произвести дальнейшую редукцию, переходя к модели
![]()
Для этой модели
![]()
![]()
![]()
![]() -Статистика критерия Проверки значимости регрессии в этой модели
-Статистика критерия Проверки значимости регрессии в этой модели
![]()
И эту модель В данном контексте можно принять за Окончательную.
С другой стороны, обнаружив при анализе модели ![]() (посредством применения T-критериев) статистическую незначимость коэффициентов при двух последних переменных, мы можем попробовать выяснить возможность Одновременного исключения из этой модели указанных объясняющих переменных, опираясь на использование соответствующего F-критерия.
(посредством применения T-критериев) статистическую незначимость коэффициентов при двух последних переменных, мы можем попробовать выяснить возможность Одновременного исключения из этой модели указанных объясняющих переменных, опираясь на использование соответствующего F-критерия.
Исключение двух последних переменных из модели ![]() соответствует гипотезе
соответствует гипотезе
![]()
При которой модель ![]() редуцируется Сразу К модели
редуцируется Сразу К модели ![]() . Критерий проверки гипотезы
. Критерий проверки гипотезы ![]() основывается на статистике
основывается на статистике
Где ![]() — остаточная сумма квадратов в модели
— остаточная сумма квадратов в модели ![]() ,
, ![]() — остаточная сумма квадратов в модели
— остаточная сумма квадратов в модели ![]() ,
, ![]() — количество зануляемых параметров,
— количество зануляемых параметров, ![]() .
.
Для наших данных получаем значение
![]()
Которое следует сравнить с критическим значением ![]() Поскольку
Поскольку ![]() , мы Не отвергаем гипотезу
, мы Не отвергаем гипотезу![]() и можем Сразу перейти от модели
и можем Сразу перейти от модели ![]() к модели
к модели ![]() .
.
Замечание. В рассмотренном примере мы действовали двумя способами:
Дважды использовали ![]() -Критерии, сначала приняв (не отвергнув) гипотезу
-Критерии, сначала приняв (не отвергнув) гипотезу ![]() в рамках модели
в рамках модели ![]() , а затем приняв гипотезу
, а затем приняв гипотезу ![]() в рамках модели
в рамках модели ![]() .
.
Однократно использовали F-Критерий, приняв гипотезу ![]() в рамках модели
в рамках модели ![]() .
.
Выводы при этих двух альтернативных подходах оказались одинаковыми. Однако, из выбора модели ![]() в подобной последовательной процедуре, вообще говоря, не следует что такой же выбор будет обязательно сделан и при применении
в подобной последовательной процедуре, вообще говоря, не следует что такой же выбор будет обязательно сделан и при применении ![]() -Критерия, сравнивающего первую и последнюю модели.
-Критерия, сравнивающего первую и последнюю модели.
| < Предыдущая | Следующая > |
|---|